SQLcl: Export and Import data with newlines
Situation
Recently I was given a seed data file that was generated from SQLcl with a bunch of INSERT statements, and it worked fine in SQL Developer when ran but would fail in SQLcl with the following:
SQL> @DEMO_DATA_TABLE.sql
Error starting at line : 3 File @ file:/Users/neiferna/bug/DEMO_DATA_TABLE.sql In command - Insert into DEMO (ID,DISPLAY_NAME) values (2,'multiline feedback
Error at Command Line : 3 Column : 46 File @ file:/Users/neiferna/bug/DEMO_DATA_TABLE.sql Error report - SQL Error: ORA-01756: quoted string not properly terminated 01756. 00000 - "quoted string not properly terminated" *Cause: A quoted string must be terminated with a single quote mark ('). *Action: Insert the closing quote and retry the statement.
More Details : https://docs.oracle.com/error-help/db/ora-01756/ 1* Insert into DEMO (ID,DISPLAY_NAME) values (2,'multiline feedback SP2-0734: unknown command beginning "2')..." - rest of line ignored.
SP2-0223: No lines in SQL Buffer.SQL>
It is common to track seed/sample data scripts, as opposed dump files. These scripts are used in releases and easy to maintain for the developer and tracked.
I went ahead and created a base case for the failure and realized that it was failing on any statements which had newlines in the INSERT. Here is a sample file named DEMO_DATA_TABLE.sql base case:
REM INSERTING into DEMO SET DEFINE OFF;
Insert into DEMO (ID,DISPLAY_NAME) values (2,'multiline feedback
1
2');
/
Solution
Shoutout to Martin D'Souza for the tip. All you need to do is the following:
set sqlblanklines on;
Problem solved.
Here is an example of the working insert with newlines:
SQL> set sqlblanklines on;
SQL> @DEMO_DATA_TABLE.sql
1 row inserted.
SQL> commit;
Commit complete.
SQL>
Other format considerations
CSV
JSON and other formats not supported by LOAD
CSV
Using SQLcl unload/load with CSV yielded a similar error due to the newlines:
SQL> set loadformat csv SQL> unload demo
format csv
column_names on delimiter , enclosures "" encoding UTF8 row_terminator default
** UNLOAD Start ** at 2024.01.16-17.09.51 Export Separate Files to /Users/neiferna/bug DATA TABLE DEMO File Name: /Users/neiferna/bug/DEMO_DATA_TABLE.csv Number of Rows Exported: 1 ** UNLOAD End ** at 2024.01.16-17.09.52 SQL> truncate table demo;
Table DEMO truncated.
SQL> load table demo DEMO_DATA_TABLE.csv
Load data into table WKSP_PRODUCTREFERENCES.DEMO
csv column_names on delimiter , enclosures "" double off encoding UTF8 row_limit off row_terminator default skip_rows 0 skip_after_names
#ERROR Insert failed for row 1
#ERROR --Line contains invalid enclosed character data or delimiter at position 21
#ERROR Row 1 data follows: 2,"multiline feedback
#ERROR Insert failed for row 5
#ERROR --Line contains invalid enclosed character data or delimiter at position 2
#ERROR Row 5 data follows: "2,
#INFO Number of rows processed: 5
#INFO Number of rows in error: 2
#INFO No rows committed
WARNING: Processed with errors
I played around with different delimeter and loadformat settings but still no luck. I will update once I hear a solution on this one.
JSON/Other formats
You can UNLOAD to JSON and some other formats, but there is no native way to LOAD back in yet. Only CSV/DELIMITED can. And INSERT format can also just be ran since it is a .sql file that is produced.
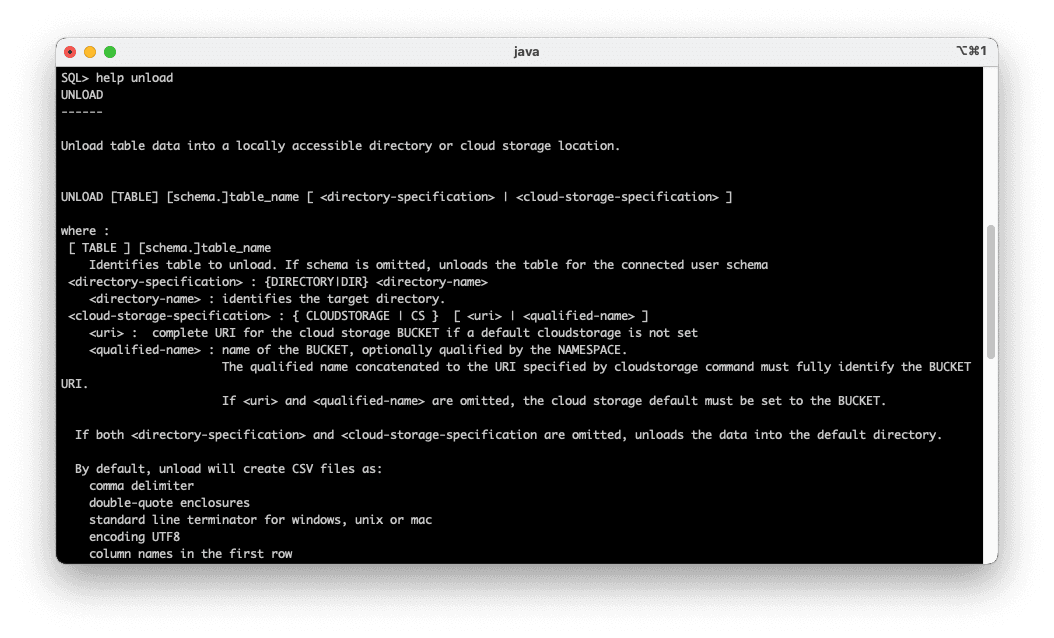
SQL> help set loadformat
default : Load format properties return to default values
csv : comma separated values
delimited : (CSV synonym) delimited format, comma separated values by default
html : UNLOAD only, Hypertext Markup Language
insert : UNLOAD only, SQL insert statements
json : UNLOAD only, Java Script Object Notation
json-formatted : UNLOAD only, "pretty" formatted JSON
loader : UNLOAD only, Oracle SQLLoader format
t2 : UNLOAD only, T2 Metrics
xml : UNLOAD only, Extensible Markup Language
xls : Excel 97- Excel 2003 Workbook format
xlsx : Excel format for version 2007 or higher
where options represents the following clauses:
COLUMN_NAMES|COLUMNNAMES|NAMES {ON|OFF} : Header row with column names
DELIMITER {separator} : Delimiter separating fields in the record
DOUBLE [OFF] : (Import only) Right enclosures embedded in the data are doubled. OFF indicates right enclosures embedded in the data are not doubled and single embedded right enclosures can lead to unexpected results.
ENCLOSURES {enclosures|OFF} : Optional left and right enclosure.
OFF indicates no enclosures
If 1 character is specified, sets left and right enclosure to this value.
If 2 or more characters are specified, sets left to the first character,
the right to the second character and ignores the remaining characters.
To set multiple character enclosures, use Set ENCLOSURE_LEFT and ENCLOSURE_RIGHT
ENCODING {encoding|OFF|""} : Encoding of load file. OFF and "" reset to default encoding for environment
LEFT|ENCLOSURE_LEFT|ENCLOSURELEFT {enclosure|OFF} : Set a 1 or more character left enclosure. If no ENCLOSURE_RIGHT is specified, it is used for both left and right.
OFF indicates no enclosures
RIGHT|ENCLOSURE_RIGHT|ENCLOSURERIGHT {enclosure|OFF} : Set a 1 or more character right enclosure.
OFF indicates no right enclosure
ROW_LIMIT|ROWLIMIT|LIMIT} {number_of_rows|OFF|""} : Max number of rows to read, including header. OFF and "" set to not limit.
SKIP|SKIP_ROWS|SKIPROWS {number_of_rows|OFF|""} : Number of rows to skip
[[SKIP_AFTER_NAMES|SKIPAFTERNAMES|AFTER]|[SKIP_BEFORE_NAMES|SKIPBEFORENAMES|BEFORE]] : Skip the rows before or after the (header) Column Names row
TERM|ROW_TERMINATOR {terminator|""|DEFAULT|CR|CRLF|LF} : Character(s) indicating end of row. If the file contains standard line end characters, the line_end does not need to be specified.
"" or DEFAULT specifies the default (any standard terminator) for LOAD
"" or DEFAULT specifies the environment default for UNLOAD
CRLF specifies WINDOWS terminator, generally for UNLOAD
LF specifies UNIX terminator, generally for UNLOAD
CR specifies MAC terminator, generally for UNLOAD
Examples:
set loadformat delimited
7369,"SMITH","CLERK",7902,17-DEC-80,800,,20,5555555555554444
set loadformat delimited enclosures <> line_end {eol}
7369,<SMITH>,<CLERK>,7902,17-DEC-80,800,,20,5555555555554444{eol}
set loadformat delimited
7369,"SMITH","CLERK",7902,17-DEC-80,800,,20,5555555555554444
set loadformat default (restore default settings)
7369,"SMITH","CLERK",7902,17-DEC-80,800,,20,5555555555554444
set loadformat xls
Set load format to old Excel versions (Excel 97-2003)
set loadformat xlsx
Set load format to newer Excel versions (Excel 2007 or higher)
Quite often developers track seed/sample data, and JSON may be preferred for some. Maybe this will be a native load format eventually that can be loaded in with LOAD - but for now here is one of the many methods to load that file in. In the past I have used a bash script that takes the JSON file locally, builds an array of strings .sql file that eventually created a clob and you can work with that clob in SQL. But below is something small and a little simpler to get going.
Here is an example of what gets produced from set loadformat json
Example JSON format from UNLOAD (with 1 row)
{
"results": [
{
"columns": [
{ "name": "ID", "type": "NUMBER" },
{ "name": "DISPLAY_NAME", "type": "VARCHAR2" }
],
"items": [{ "id": 2, "display_name": "multiline feedback\n\n1\n\n2" }]
}
]
}
Inserting using JSON
There are various ways to get a file into the database. Examples: PUT into a RESTful ORDS service and store in a table, etc. The following example shows how to use an OCI bucket as a temporary data storage to load the file from you desktop then read in the database.
- Load the export into a Bucket in Object Storage (examples can be found here)
SQL> set loadformat json
SQL> oci profile PERSONAL Region set to: us-ashburn-1 OCI Profile set to PERSONAL Transfer method set to oci
SQL> cs https://objectstorage.us-ashburn-1.oraclecloud.com/n//b/demo-image-upload DBMS_CLOUD Credential: Not Set OCI Profile: PERSONAL Transfer Method: oci URI as specified: https://objectstorage.us-ashburn-1.oraclecloud.com/n//b/demo-image-upload
SQL> unload demo CS
DBMS_CLOUD Credential: Not Set OCI Profile: PERSONAL Transfer Method: oci URI as specified: https://objectstorage.us-ashburn-1.oraclecloud.com/n//b/demo-image-upload Final URI: https://objectstorage.us-ashburn-1.oraclecloud.com/n//b/demo-image-upload
format json
** UNLOAD Start ** at 2024.01.22-23.17.10 Export Separate Files to https://objectstorage.us-ashburn-1.oraclecloud.com/n//b/demo-image-upload DATA TABLE DEMO File Name: DEMO_DATA_TABLE_2.json Number of Rows Exported: 1 ** UNLOAD End ** at 2024.01.22-23.17.11
- Pull the file with
apex_web_service.make_rest_requestand insert with the help ofJSON_TABLE
declare l_clob clob;
begin
l_clob := apex_web_service.make_rest_request(
p_url => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n//b/demo-image-upload/DEMO_DATA_TABLE_2.json',
p_http_method => 'GET'
);
insert into demo( id, display_name ) select * from json_table(l_clob, '$.results[].items[]' columns( id number path '$.id', display_name varchar2(4000) path '$.display_name' ) ); end;
You just need to modify the columns to fit your needs, and I am sure this insert/select can be dynamically created based on the results.columns in the JSON.



